El consumo de energía ultra bajo (activo y en espera) y la respuesta en tiempo real son factores clave con los altavoces inteligentes de control de voz alimentados por batería. El rendimiento y el coste del sistema pueden optimizarse con la elección adecuada de la arquitectura de memoria flash.
Una implementación popular de la inteligencia artificial (IA) es un altavoz inteligente alimentado por batería con control de voz. El dispositivo se activa con la voz, respondiendo a una palabra de alerta como «Allegra», «Odessa» o «Adesto». Una vez despierto, un asistente virtual se encarga de las demás órdenes de voz.
- En el caso de los altavoces inteligentes que funcionan con baterías, los usuarios quieren una larga duración de las mismas, por lo que el sistema debe tener un consumo de energía ultra bajo mientras está en estado de reposo.
- Los usuarios también esperan una respuesta inmediata del dispositivo una vez que pronuncian su palabra de comando.
A diferencia de muchos dispositivos similares que se encuentran actualmente en el mercado, el objetivo del altavoz inteligente descrito aquí es mantener el consumo de energía promedio lo suficientemente bajo como para permitir que el dispositivo funcione con baterías. No debería ser necesario estar conectado a la energía externa todo el tiempo. Por lo tanto, debe ser un sistema de IA de bajo consumo.
Para entender cómo funciona un altavoz tan inteligente, examinemos el sistema en general. La IA se basa en dos modos de operación distintos: la fase de aprendizaje, que es cuando el sistema aprende las características de los tipos de datos en los que está operando, y la fase de inferencia, en la que el sistema utiliza lo que ya ha aprendido para interpretar nuevos datos.
La fase de aprendizaje consiste en alimentar al sistema con grandes cantidades de datos conocidos y construir un conjunto de tablas de inferencia como resultado. Esto requiere mucha potencia de computación y/o tiempo. Para un dispositivo periférico, la fase de aprendizaje no se hace en el propio dispositivo. Se hace «de una vez por todas» en un gran sistema informático, y las tablas de inferencia resultantes se almacenan como tablas de datos fijas en el dispositivo de borde.
La fase de inferencia es la fase de reconocimiento de palabras. Esto se repite cada vez que el dispositivo recibe nuevos datos. Para la fase de despertar, por ejemplo, es escuchar una palabra hablada y usar las tablas de inferencia almacenadas en el dispositivo para determinar si la palabra que acaba de escuchar es su palabra mágica de despertar.
Un tema central
Los algoritmos de IA en tiempo real requieren una gran cantidad de potencia de CPU, por lo que nuestro sistema necesita una gran y potente CPU con mucha memoria. Al mismo tiempo, los usuarios quieren una larga duración de la batería, por lo que el sistema debe tener un consumo de energía ultra bajo mientras los algoritmos de IA intentan detectar la palabra de alarma. Los usuarios también esperan una respuesta inmediata del dispositivo una vez que pronuncian su palabra de comando. La parte del sistema que reconoce la palabra de activación necesita, por lo tanto, un tiempo de respuesta muy rápido.
Todos estos requisitos son difíciles de lograr con sólo un núcleo de CPU y un sistema de memoria. El uso de dos o más núcleos, con diferentes sistemas de memoria, es probablemente una solución más rentable. Puede tratarse de dos MCU separadas o de un sistema de un solo chip (SoC) con una CPU de varios núcleos.
La CPU principal podría ser un único MCU, una CPU de varios núcleos, un acelerador de IA, una GPU o cualquier combinación de estos. La cantidad de memoria necesaria va desde unos pocos cientos de megabytes hasta varios gigabytes. Los sistemas que se limitan a manejar sólo unos pocos comandos hablados son capaces de operar con mucha menos memoria.
En la configuración que se muestra en la Figura 2, la CPU principal se encargará de la mayor parte del procesamiento de la IA local. También puede llamar a la nave nodriza en la nube según sea necesario. En nuestro ejemplo, gran parte del procesamiento pesado no tendrá lugar dentro del propio altavoz inteligente, sino en un servidor de sistema remoto en un centro de datos.
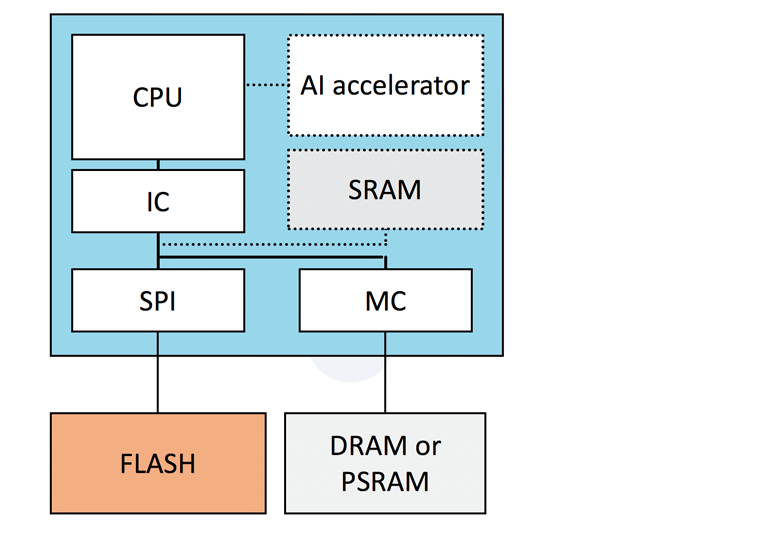
En esta configuración, la CPU arrancará desde una memoria flash externa (memoria grande NOR o NAND no volátil) y se ejecutará desde la DRAM o PSRAM externa más rápida. Para ahorrar energía, la CPU principal se apagará cuando no esté en uso y las memorias DRAM y SRAM, que requieren mucha energía, se apagarán mientras el dispositivo esté en modo de suspensión.
La CPU principal sólo se despertará después de que se haya recibido y reconocido la palabra de activación. Esto significa necesariamente que habrá un cierto retraso cada vez que se despierte para recargar las memorias.
Siempre en la CPU
Mientras la CPU principal está durmiendo, y durante el tiempo que le toma a la CPU principal recargar sus memorias, la CPU siempre activa estará a cargo. La principal tarea del CPU siempre activo es escuchar los sonidos entrantes, detectar y reconocer la palabra de alerta, y luego alertar al CPU principal cuando sea necesario. Como mínimo, requerirá suficiente capacidad de IA para reconocer una sola palabra hablada. Una vez que detecte la palabra correcta, despertará a la CPU principal y dejará que el grandote se encargue de ello.
La CPU siempre activa también puede manejar otras tareas que no requieren una IA avanzada; por ejemplo, tareas domésticas y reproducción de audio. Esto significa que la CPU principal puede volver a dormirse relativamente rápido, mientras que la CPU siempre activa se encarga del resto. La cantidad de memoria que requiere la CPU siempre activa para realizar sus tareas sencillas es mucho menor que la que requiere la CPU principal.
La CPU siempre activa también puede apagarse cuando no se utiliza, siempre que se despierte lo suficientemente rápido. Por ejemplo, puede dormir hasta que el micrófono detecte el sonido, pero debe ser capaz de empezar a ejecutarse lo suficientemente rápido como para captar el inicio de una palabra hablada.
Esto dificulta el uso de un boot+SRAM como configuración de memoria para la CPU siempre activa. La cantidad de memoria necesaria para las aplicaciones de IA significa que la SRAM en el chip sería costosa, y el requisito de tiempo de respuesta significa que no hay tiempo para recargar la memoria. La SRAM tendría que mantenerse encendida todo el tiempo, lo que daría lugar a un alto consumo de energía. Para reducir el tamaño de la SRAM, sería posible mantener sólo el código en la SRAM y mantener las tablas de inferencia de la IA en flash. Pero esta opción seguiría consumiendo energía.

En los sistemas que utilizan shadow flash (o memoria de arranque) + SRAM incrustada, la memoria flash suele contener la imagen de código original de fábrica, la imagen de código utilizada actualmente y espacio para almacenar una imagen entrante actualizada por OTA.
La memoria flash embebida podría manejar el requisito de tiempo de activación, pero tiene sus inconvenientes.
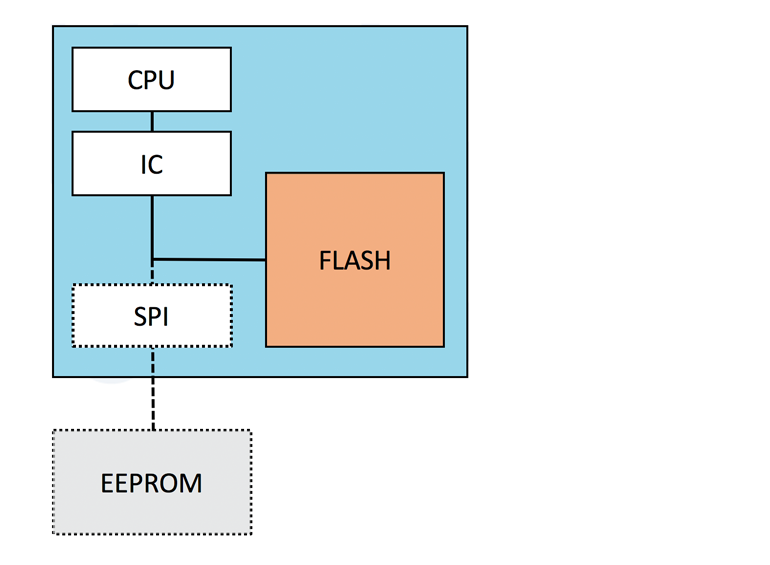
Esta configuración de NVM integrada ofrece la mejor energía de reserva. Sin embargo, el flash incorporado puede ser caro.
El almacenamiento de código no volátil está en el mismo dado que la CPU, lo que ahorra tiempo y energía. Sin embargo, el gran requerimiento de memoria es costoso. Además, el uso de NVM embebida significa que la CPU siempre activa no puede colocarse en el mismo dado que la CPU principal, ya que ésta suele ser demasiado grande para implementarse en un proceso de NVM embebida. O, si realmente quisiéramos mantener ambas CPU en el mismo dado usando un proceso de NVM embebido, la CPU principal sería considerablemente más cara de lo necesario.
Memoria XiP
El uso de una memoria de ejecución (XiP) como almacenamiento de código es la opción más viable para la CPU siempre activa. En una configuración XiP (Fig. 5), la CPU está construida con una caché de instrucciones (IC). Cada vez que la CPU obtiene una instrucción, primero comprobará la memoria caché para ver si la ubicación de esa dirección ya ha sido cargada en el dispositivo. Si lo ha hecho, la CPU cargará la instrucción desde el caché, y si no, iniciará una operación de lectura desde el flash para llenar la línea de caché que falta.
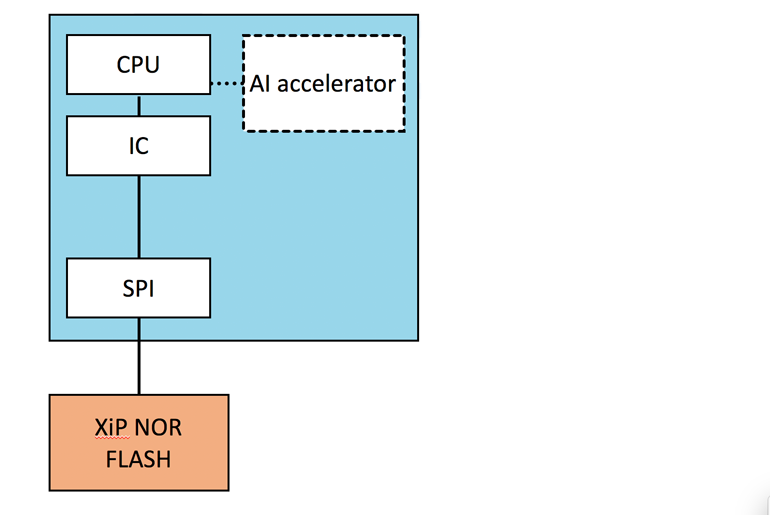
Para la CPU siempre activa con configuración XiP, la principal tarea de la CPU siempre activa es escuchar los sonidos entrantes, detectar y reconocer la palabra de activación, y luego alertar a la CPU principal.
A pesar de que un sistema XiP utiliza un dado separado para el flash, tiene muchas de las mismas características que un dispositivo de flash incorporado. La energía de espera o de reposo puede llegar al mismo rango de submicroamperios que los dispositivos de flash integrados. Al mismo tiempo, los tiempos de activación estarán en el rango de microsegundos a unos pocos milisegundos, al igual que los sistemas que utilizan flash incorporado.
En las aplicaciones de IA, el motor de inferencia necesita pasar por un gran número de coeficientes de almacenamiento de NVM en un tiempo muy corto y con un mínimo consumo de energía. Los conjuntos de datos son demasiado grandes para caber en la memoria caché, por lo que el ancho de banda en bruto de la interfaz entre el flash y el controlador de host se convierte en el factor crítico para obtener el máximo rendimiento.
Conseguir que una solución XiP se implemente correctamente no es tan fácil si se intenta utilizar la flash estándar para este fin. Durante décadas, el principal propósito de los dispositivos de flash estándar ha sido servir como memoria de arranque para los sistemas de flash de sombra. Aunque estas memorias han sido optimizadas para servir muy bien a esa aplicación, se quedan cortas en su uso como memoria XiP.
Específicamente, como memoria XiP, la flash serie estándar ofrece un rendimiento mucho más bajo de lo que uno desearía ver, y el consumo de energía es alto tanto en el modo operativo como en el modo de suspensión. La flash estándar sólo puede funcionar a 104 o 133 MHz en el modo SDR (SDR es el modo de velocidad de datos única, a veces denominado velocidad de transferencia única o modo STR). Incluso cuando se ejecuta en un modo cuádruple, el rendimiento máximo se limita a 52 o 66 MB/s.
Aplicación de una interfaz DDR octal
Aquí es donde una interfaz DDR octal, como la EcoXiP de Adesto, realmente muestra una diferencia en comparación con un dispositivo SPI cuádruple. EcoXiP es una memoria no volátil específica para aplicaciones con un rendimiento de hasta 300 Mbytes/s, así como de bajo costo y bajo consumo de energía para diseños de microcontroladores que utilizan una arquitectura de ejecución en el lugar.
EcoXiP está diseñado desde el principio con los sistemas XiP en mente, y apunta específicamente a la operación de baja potencia. Soporta la transferencia de datos a alta velocidad en ambos modos octal y cuádruple y ofrece velocidades de datos duales y simples para ambos. Además, EcoXiP tiene funciones diseñadas para proporcionar una mejor latencia y rendimiento para las arquitecturas de CPU en caché.
Una característica única que ofrece EcoXiP es la lectura y escritura simultáneas sin retraso adicional en las operaciones de lectura. Si se ha iniciado un programa u operación de borrado en una parte de la memoria, el dispositivo puede seguir leyendo desde otra parte de la memoria sin ningún retraso. Esto simplifica significativamente las operaciones de registro de datos y las actualizaciones por aire para los dispositivos sin memoria de programa en el chip.
Resumen
Para las aplicaciones de IA en el borde, el rendimiento y el costo del sistema dependerá directamente del rendimiento y el costo de la memoria. La DRAM externa requiere mucha energía, la flash SPI cuádruple externa es demasiado lenta, y la flash interna integrada es demasiado pequeña o demasiado cara.
La memoria XiP como almacenamiento de código es claramente la mejor opción para la CPU siempre activa de los sistemas de IA. Sin NVMs embebidas en ninguna de las CPUs, es entonces fácil añadir ambas al mismo dado y crear un SoC.